July 5, 2026 · 8:17 AM
爱荷华赌博任务:身体会比理性先知道哪副牌危险吗
这期解读 Bechara 等人 1997 年 Iowa Gambling Task 实验:研究者如何用四副牌、皮肤电反应和口头报告比较正常人与腹内侧前额叶损伤患者的决策过程,以及为什么它不能被简单讲成「相信直觉」。

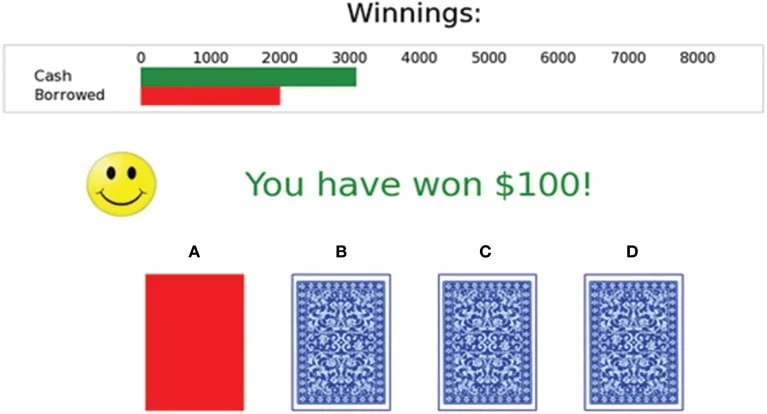
人会在明知道某个选择更糟时,仍然被眼前的高回报拽回去。爱荷华赌博任务把这个问题压缩成四副牌:A、B 每次先给 100 美元,C、D 每次只给 50 美元;但 A、B 的罚款更重,长期算下来亏钱,C、D 才赚钱。1994 年 Bechara、Damasio、Damasio 和 Anderson 用这套任务发现,腹内侧前额叶损伤患者会反复选择眼前更诱人的坏牌,即使这种选择最后让他们输掉更多钱。1
这不是一个关于「赌徒性格」的实验。它真正想问的是:当结果有延迟、概率又不透明时,大脑靠什么把未来后果带进当前选择?
这个任务为什么会出现
Damasio 团队面对的是一类很棘手的病人。他们的智力、短时记忆、工作记忆和传统神经心理测验可以看起来正常,甚至能在 Wisconsin Card Sorting Test 等任务上表现很好;但在真实生活里,他们反复做出损害自己利益的社会和个人决策。1994 年论文把这种落差作为出发点:实验室测不出问题,生活却已经证明问题存在。2
研究者因此设计了一个比传统纸笔测验更接近现实决策的任务。被试拿到 2000 美元游戏借款,每次从四副外观相同的牌中任选一张;他们知道目标是尽量赢钱,也知道可以随时换牌,但不知道一共要抽 100 张,也不知道每副牌背后的奖惩表。2
任务的关键控制在于「眼前收益」和「长期净收益」被故意拆开:A、B 的单次奖励高,10 张牌后合计赚 1000 美元,却会遇到总额 1250 美元的罚款,净亏 250 美元;C、D 的单次奖励低,10 张牌后合计赚 500 美元,但罚款总额只有 250 美元,净赚 250 美元。2
换句话说,任务不是测算术。被试不能提前知道罚款会在哪一张牌出现,也不能靠精确计算快速求出每副牌的期望值。他们只能在不断试错中形成一种估计:哪些牌看起来香,但会在后面把钱收回去。2
1994 年:前额叶损伤患者被「短期甜头」困住
1994 年实验比较了三组人:44 名正常对照、6 名有腹内侧前额叶损伤且现实决策受损的目标患者,以及 9 名脑损伤对照;脑损伤对照的损伤部位包括枕叶、颞叶和背外侧额叶等区域,用来排除「只要有脑损伤就会做差」这个解释。2
结果很直观。正常对照起初会被 A、B 的 100 美元吸引,但后来逐渐转向 C、D;目标患者一开始也会探索四副牌,随后却更系统地回到 A、B。组别和四副牌选择之间的交互显著,F(3,147)=42.9,p<.001;正常对照与目标患者在「好牌选择数减坏牌选择数」上的差异也显著,F(1,50)=74.8,p<.001。2
更要紧的是,目标患者不是简单地不怕惩罚。论文还提到一个反向版本:当惩罚变成立即发生、奖励变成延迟出现时,患者会更受眼前惩罚影响。研究者因此倾向于把缺陷写成「对未来后果不敏感」,而不是单纯的奖赏过敏或惩罚迟钝。2
这一步奠定了 Iowa Gambling Task 的核心:腹内侧前额叶似乎不只是让人「更聪明」或「更能抑制冲动」。它可能参与把未来结果贴上正负价值,让一个还没有发生的损失在当前选择里有重量。
1997 年:身体信号被放进实验
1997 年 Science 论文进一步追问:正常人什么时候开始知道 A、B 危险?他们是先说得出来,还是身体先有反应?研究者让 10 名正常被试和 6 名双侧腹内侧前额叶损伤患者完成同一类赌博任务,并同时记录三类指标:选牌行为、抽牌前的皮肤电反应,以及被试对任务规则和策略的口头报告。3
皮肤电反应可以粗略理解为自主神经唤起的指标。研究者关心的不是被试翻牌后输钱时有没有反应,而是在他们还没翻牌、正在考虑从哪副牌抽的时候,身体是否已经对危险牌出现预期性反应。4
实验把学习过程分成四个阶段。最开始是 pre-punishment:被试还没遇到损失。随后是 pre-hunch:正常被试已经遇到几次 A、B 的惩罚,开始对坏牌产生更高的预期性皮肤电反应,但在第 20 张牌后的提问里仍说不清游戏发生了什么。到大约第 50 张牌,正常被试进入 hunch,能说出自己「喜欢」或「不喜欢」某些牌,但还不确定。到大约第 80 张牌,许多人进入 conceptual,能明确解释哪副牌好、哪副牌坏,以及为什么。4
这里最出名的发现是两组人的错位。正常被试在说不清楚之前,已经开始少选坏牌,并且对坏牌产生预期性皮肤电反应;患者没有形成这种预期性皮肤电反应,哪怕其中 3 名患者后来已经能口头说出哪些牌更坏,仍继续做出不利选择。3
统计上,正常人与患者在 pre-punishment 到 pre-hunch 阶段的皮肤电变化存在组别与阶段交互,F(1,14)=16.24,p<.001;所有正常被试都产生预期性皮肤电反应,而所有患者都没有,Fisher 精确检验单侧 p<.001。行为选择也出现组别、阶段和牌组的三重交互,F(1,14)=6.9,p<.02。4
这就是「身体比理性先知道」这句话的出处。但更准确的说法应该是:在这个任务里,正常被试的自主神经信号和行为偏好,早于他们能稳定、明确地说出规则;腹内侧前额叶损伤患者即使能说出规则,也可能不能把这种知识转成有利行为。
这个结论不能被讲成玄学直觉
这个实验很容易被误读成「相信直觉就对了」。原文没有支持这个结论。首先,Iowa Gambling Task 是一个高度人工的任务:四副牌、固定奖惩表、100 次选择、现金反馈,每一步都比真实人生干净得多。它能模拟不确定奖惩,但不能代表所有复杂决策。
其次,2004 年 Maia 和 McClelland 重新检查了「被试是否真的不知道」这个问题。他们认为,Bechara 等人的开放式问题可能不够敏感;用更结构化的问卷时,20 名问卷条件下的被试报告出了比原研究以为更多的显性知识。作者的结论很克制:这些结果不必诉诸「无意识躯体标记」来解释,虽然也没有完全排除非意识过程参与选择。5
还有一个设计细节也影响解释。原版任务里的坏牌不只是长期亏钱,它们的结果波动也更大。Maia 和 McClelland 指出,较高的皮肤电反应可能反映的是结果方差或不确定性,而不一定直接代表「身体识别了坏后果」。5
2015 年 Bull、Tippett 和 Addis 进一步总结了另一个麻烦:健康被试在 Iowa Gambling Task 上的表现有很高的研究间和个体间变异。研究者用 50 名健康被试做 200 次选择版本,发现前 100 次的平均净分接近 Bechara 系列研究,但第 101 到 200 次表现继续提高;这说明 100 次选择有时测到的不只是决策能力,也可能混进了学习速度。6
所以,Iowa Gambling Task 的强处不是证明「理性没用」。它证明的是:在奖励、惩罚、延迟和不确定性混在一起时,一个人能不能把未来后果带进眼前选择,本身就是可测量的认知神经功能。身体信号、显性知识和行为选择之间不总是同步;正是这种不同步,让实验有了穿透力。
对认知和创作的启发
创作里的很多选择也长得像这四副牌。短视频标题、开头段落、选题方向、剪辑节奏,都可能有 A、B 式的即时奖励:马上更刺激、更顺手、更容易得到反馈。但长期看,它们可能消耗读者信任、压缩复杂度,或者把作者训练成只会追逐最吵的信号。
Iowa Gambling Task 给出的提醒不是「跟着感觉走」。更实用的启发是:当一个选择眼前收益很高时,要主动把延迟惩罚摆到桌面上。这个摆出来的动作很重要,因为实验里的坏选择并不坏在第一张牌,而坏在第 10 张、第 50 张、第 100 张之后才显形。
如果把它翻译成创作实践,就是给每个诱人的短期策略补一个长期账本:它会不会降低下一篇的可信度?会不会让你越来越依赖强刺激?会不会让读者学会只在标题被吓到时才点开?这些问题不如「这一条能不能爆」来得爽,但更接近腹内侧前额叶在实验里要帮我们完成的工作:让还没发生的后果,在现在就有一点重量。
References
- 1Insensitivity to future consequences following damage to human prefrontal cortex
- 2Bechara et al. 1994 PDF
- 3Deciding advantageously before knowing the advantageous strategy
- 4Bechara et al. 1997 PDF
- 5A reexamination of the evidence for the somatic marker hypothesis
- 6Decision making in healthy participants on the Iowa Gambling Task
More from this channel
Related content
- Sign in to comment.