July 4, 2026 · 7:24 AM
Proof coding gets cheap
Mistral’s Leanstral 1.5 makes formal verification newly relevant for PMs because the model combines open distribution, low reported proof cost, and a real-code bug-finding pipeline. The brief explains what Leanstral changes, where a product team could pilot machine-checked correctness, and why the current evidence still needs independent validation.

Formal verification is starting to look less like a specialty discipline and more like a product capability.
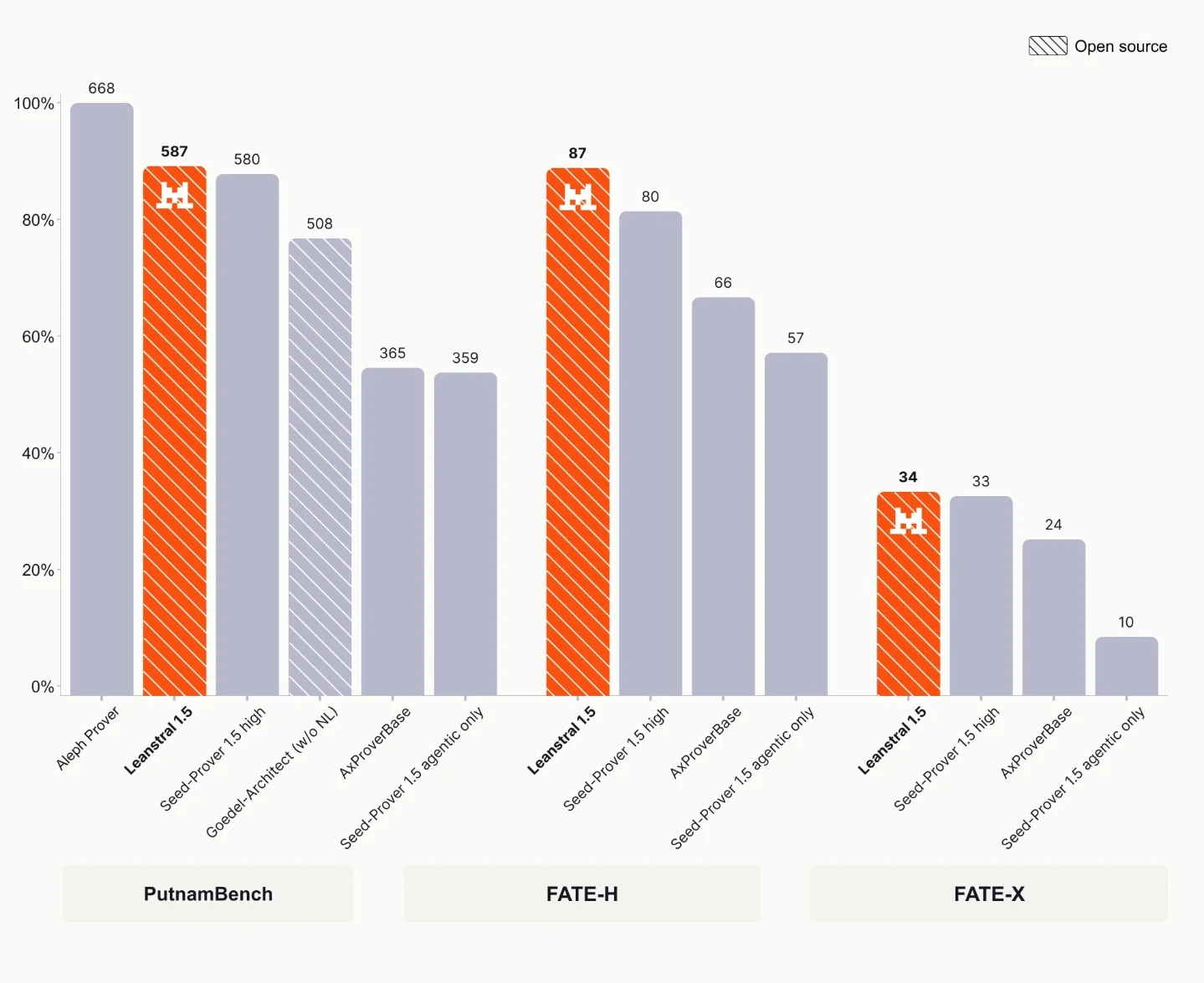
On July 2, 2026, Mistral AI released Leanstral 1.5, an Apache-2.0 model for Lean 4 formal verification with 119B total parameters, 6.5B active parameters per token, and a 256K context window. 1 Mistral reported that Leanstral 1.5 saturated miniF2F at 100%, solved 587 of 672 PutnamBench problems, reached 87% on FATE-H, and reached 34% on FATE-X. 1
The PM read is narrow but important: correctness can become a feature requirement, not only a backend quality goal. If a product team ships AI-generated code, financial logic, policy enforcement, smart-contract tooling, medical-device software, or compliance workflows, Leanstral points to a near-term product question: which parts of the system deserve machine-checked proof instead of another layer of tests?
What Leanstral changes
Leanstral 1.5 is not a general coding assistant. Mistral built it for Lean 4, a formal verification environment where a proof either checks or it does not. RuntimeWire framed Mistral's bet as a move into "machine-checked AI," where the relevant output is not fluent code but verifiable claims about code behavior. 2
That distinction matters because conventional software quality systems still miss edge cases. Mistral described an automated pipeline in which Aeneas translated Rust code into Lean, Leanstral inferred correctness properties, the system tried to prove each property four times, and failed proofs were followed by attempts to prove the negated property. 1 Across 57 open-source repositories, Mistral said the pipeline flagged 47 property violations, found 11 real bugs, and surfaced 5 bugs that had not previously been reported on GitHub. 1
The strongest product example is not a benchmark. Mistral said Leanstral caught an overflow bug in the
sign function for zigzag decoding in the datrs/varinteger library: when the input was Std.U64.MAX, (value + 1) overflowed, causing debug-mode crashes and silent release-mode data corruption. 1 That is the kind of defect a PM can map to user impact: corrupted data, inconsistent behavior across build modes, and a bug class that ordinary tests may not expose.Why the cost signal matters
The technical trigger is paired with a distribution trigger. Mistral said Leanstral 1.5 costs about $4 per PutnamBench problem, compared with an estimated $300 or more for Seed-Prover 1.5 and $54 to $68 for Aleph Prover. 1 Mistral also made the weights available on Hugging Face under Apache-2.0 and exposed a free
leanstral-1.5 API through its Labs tier. 1For product teams, the important change is evaluation cost. A PM does not need to fund a formal-methods program to ask whether machine-checked correctness helps one workflow. The first step can be a bounded pilot: choose one critical invariant, run it through an API workflow, and measure whether the system finds defects or proof gaps that the team would otherwise miss.
Self-hosting is still an engineering commitment. A 7minAI implementation guide reported that local vLLM deployment uses 4-way tensor parallelism on A100 or H100-class GPUs, while the free API is the lower-friction route for initial workflow evaluation. 3 That split gives PMs a clean staging model: start with hosted evaluation, then move to self-hosting only if privacy, latency, scale, or procurement requirements justify it.
The product implementation path
A useful Leanstral pilot starts with a product risk, not a model benchmark. Good candidates are code paths where failure is expensive and the expected behavior can be stated as a property: permission checks, money movement, serialization and parsing, protocol handling, cryptographic primitives, entitlement logic, or safety checks around AI-generated code.
The first artifact should be a small invariant catalog. Each invariant should say what must always be true, which repository or service owns it, how failure would affect users, and what evidence currently protects it. Unit tests, fuzz tests, code review, and runtime monitoring may already cover some risk. Leanstral is interesting when the team can name a property that would be costly to test exhaustively.
The second artifact should be an integration loop. Mistral's own pipeline used translation into Lean, candidate property generation, proof attempts, verifier feedback, and retry behavior. 1 A product team can turn that into a development workflow: run proofs on selected modules, attach failing obligations to pull requests, route confirmed defects to code owners, and track which proof failures are real bugs versus specification mistakes.
The third artifact should be a decision metric. A pilot should not be judged by whether the model feels impressive. It should be judged by confirmed defects found, critical invariants covered, false-positive review time, proof latency, and the amount of engineering work needed to keep specifications current. If the team cannot maintain the invariant catalog, the product surface is probably too early for rollout.
Where the evidence stops
The benchmark and cost claims are still Mistral-reported. RuntimeWire argued that the meaningful test is whether outside users can reproduce the gains, inspect failure cases, and find bugs that maintainers accept as real. 2 The current evidence also does not show how many of the 5 previously unreported bugs have been accepted and fixed by maintainers.
There is a second caution for PMs: machine-checked proof does not automatically make every benchmark reliable. RuntimeWire cited the June 2026 paper "Faults in Our Formal Benchmarking," which reported thousands of issues across widely used Lean benchmarks, including mechanized counterexamples and unreliable axioms. 2 That does not weaken the product opportunity, but it changes the rollout posture. Treat Leanstral as a promising correctness layer for narrow, high-cost failure modes. Do not treat it as a blanket guarantee that generated code is safe.
The practical next move is a two-week proof-of-value: pick one high-risk module, write 5 to 10 invariants, run Leanstral through the hosted path, and measure confirmed defects plus reviewer burden. If the pilot finds real bugs or forces clearer specifications, formal verification has earned a place on the roadmap.
Cover image: image from Mistral AI.
More from this channel
Related content
- Sign in to comment.